<概要>
GPU + PyTorchを使った教師ありのミニバッチ学習の具体的な方法を説明します。
モデルの本体のモジュールクラスやDataLoader等の各論については以下の<関連記事>を参照してください。
個別の細かい設定、例えば torch.optim.lr_scheduler による学習率の管理などは触れません。
<関連記事>
import os
import torch
import torch.nn as nnディレクトリ構成
実際のプロジェクトでは、「モデルの定義」や「データの読み込み処理」を別ファイルに分けることで、コードの見通しが良くなり、再利用もしやすくなります。
本記事ではこれらが model.py (書き方はこちらを参照)や dataloader.py (こちらを参照)に記述されているものと仮定し、訓練ループに重点を置きます。
学習を行う本体のコードは以下の train.py にかかれているものとします。
project/
│
├── train.py # 訓練のメインスクリプト
├── model.py # MyModelの定義 (モジュールクラス)
└── dataloader.py # train_loader, val_loader の定義訓練コードと全体像
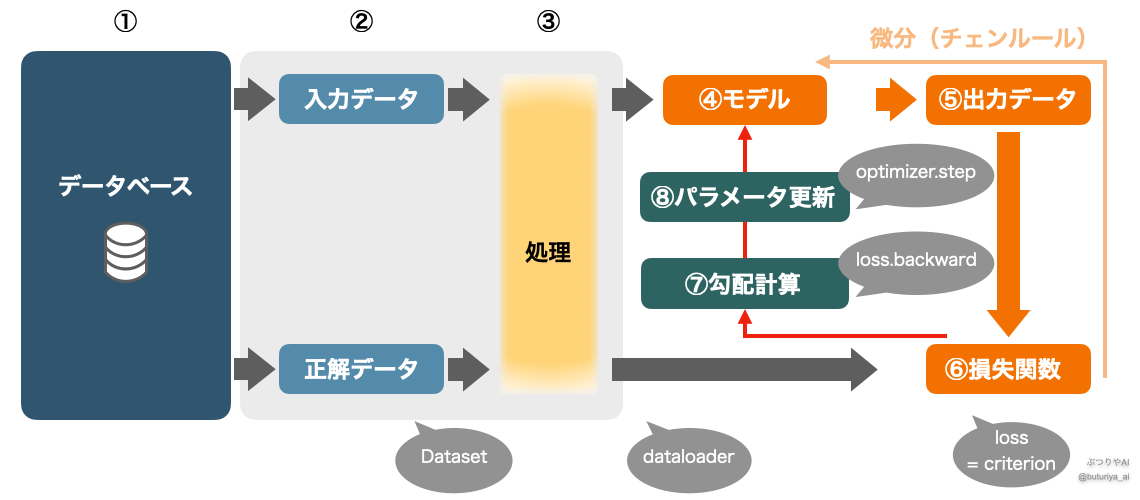
本記事のメインである、ディープラーニングで教師ありミニバッチ学習を行う最小限のコードは以下の通り、30 行ほど(コメント除く)になります。コードの下に、コードと対応する形で訓練全体をまとめたフローチャートがあります。
# train.py
import os
import torch
from model import MyModel
from dataloader import train_loader, val_loader
##############
# 1. 初期設定 #
##############
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 1-1 モデルのロード・GPUへの以降
model = MyModel().to(device)
model.train()
# 1-2 データローダー
train_loader = get_dataloader(cfg, train)
val_loader = get_dataloader(cfg, val)
# 1- 3 損失関数と最適化手法(optimizer)
criterion = torch.nn.CrossEntropyLoss().to(device) # 多クラス分類想定
optimizer = torch.optim.Adam
#############
# 2 学習開始 #
#############
for epoch in range(num_epochs):
# 2-1 訓練のループ(バッチ)
for inputs, targets in train_loader:
# 2-1-0 勾配を初期化
optimizer.zero_grad()
# 2-1-1 データをGPUへ
inputs = inputs.to(device)
targets = targets.to(device)
# 2-1-2 順伝播と損失計算
outputs = model(inputs)
loss = criterion(outputs, targets)
# 2-1-3 勾配計算と誤差逆伝播
loss.backward()
optimizer.step()
# 2-2 検証
model.eval()
val_loss = 0.0
# 勾配計算を無効化(メモリの節約・事故防止)
with torch.no_grad():
for inputs, targets in val_loader:
# 2-2-1 データをGPUへ
inputs = inputs.to(device)
targets = targets.to(device)
# 2-2-2 順伝搬と損失計算
outputs = model(inputs)
val_loss += criterion(outputs, targets)
print(f'val loss: {val_loss}')
def get_dataloader(cfg, train=True):
dataset = MyDataset(cfg.data_path, train=train)
return DataLoader(dataset, batch_size=cfg.batch_size, shuffle=train)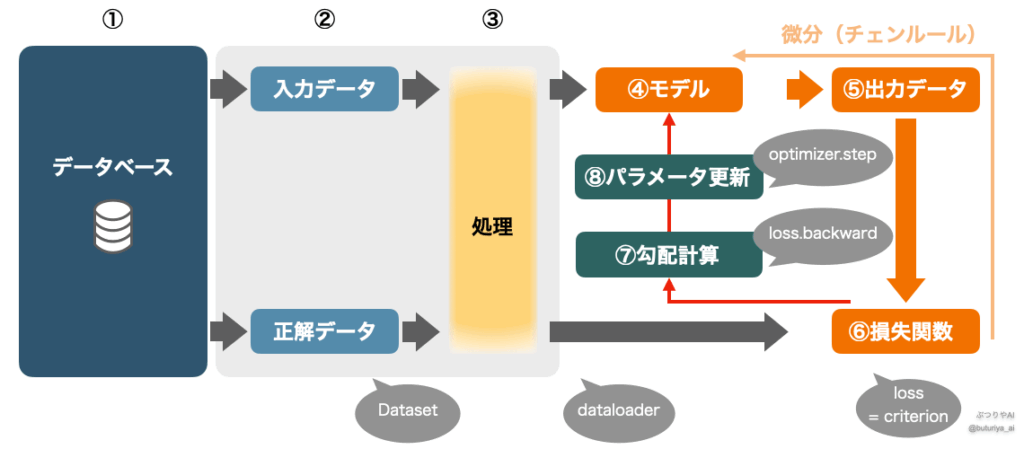
ここからは、コードの「初期設定」、「訓練ループ」それぞれをいくつかに分けた各論が続きます。
初期設定
GPU設定
PyTorchでは、GPUが使用可能であればGPUを使い、そうでなければCPUを使うように設定するのが一般的です。
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')ここでは、複数GPUがある場合に「使いたいGPUを番号で指定」するために環境変数 CUDA_VISIBLE_DEVICES を設定しています。詳細なGPUの扱いについては、PyTorchによるGPU環境設定を参照してください。
モデル
model.py に定義されている MyModel クラスを読み込み、GPUに転送します。
model = MyModel().to(device)
model.train().train() はモデルを「訓練モード」に設定するためのものです(例えば Dropout や BatchNorm の挙動は、一般的に訓練時と推論時で異なります)。推論時は .eval() に切り替えます(後述)。
モデル定義の詳細は 実践基礎9 PyTorchモデルの全体構造と作り方を理解しよう を参照。
DataLoader
訓練データと検証データの読み込みは、dataloader.py に定義されている関数 get_dataloader() を通じて行います。
train_loader = get_dataloader(cfg, train=True)
val_loader = get_dataloader(cfg, train=False)get_dataloader はコードの最後に定義されています。cfg はDataLoader や Dataset に渡す引数を含み、argparse 等で作ることを想定しています。
引数の渡し方はDataset の設計次第で、例えば辞書形式でも構いません。また、引数 train を元に Dataset が訓練・検証データを適切に準備すると仮定しています。
DataLoaderの基本は 実践基礎6 PyTorchのDatasetとDataLoaderを理解しよう を参照。
損失関数と最適化手法
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)ここでは、回帰タスクを想定して MSELoss(平均二乗誤差)を使用し、Adamオプティマイザを選択しています。
- criterion: 「正解とのズレを数値で表す」役割。分類なら
CrossEntropyLossなど。 - optimizer: 「どうやってパラメータを更新するか」の方法を定める。
自分で損失関数を定義することも可能ですが、PyTorchの組み込み関数は安定性・高速性の点で優れており、特に複雑な損失関数では、不必要に自前で実装することはおすすめしません。
損失関数の自動微分の仕組みは 実践基礎8 Tensorの自動微分を理解しよう を参照。
訓練ループの実装
訓練処理は for epoch in range(num_epochs) のループで構成されており、各エポックにおいて全てのミニバッチに対して以下の手順が実行されます。
- 勾配の初期化:
optimizer.zero_grad()で前のバッチの勾配情報をクリアします。これをしないと勾配が蓄積されてしまいます。 - データの転送: 各バッチの
inputsとtargetsをGPUに移します。DataLoaderでは転送せず、GPUが必要になる直前のこのタイミングで転送するのが一般的です。 - 順伝播と損失計算: モデルに入力を通して出力を得た後、
criterionを使って損失を計算します。 - 誤差逆伝播とパラメータ更新:
loss.backward()で勾配を計算し、optimizer.step()によりモデルのパラメータを更新します。
for epoch in range(num_epochs):
for inputs, targets in train_loader:
optimizer.zero_grad()
inputs = inputs.to(device)
targets = targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()この一連の処理をエポック(データセット全体を一巡する単位)ごとに繰り返します。
PyTorchではこのようなミニバッチ単位の訓練ループを明示的に記述することで、学習の挙動を柔軟にカスタマイズできます。
検証
検証のバッチループは「2-1 訓練のループ」とだいたい同じですが、勾配の初期化と計算、誤差逆伝播は行いません。あくまで検証データでの loss 等の計算と出力だけが目的です。with torch.no_grad()でインデントした塊の中では勾配計算を禁止することができます。
まとめ
本記事では、PyTorch + GPU を用いた教師あり学習の最小構成を通して、モデルの訓練全体の流れを解説しました。
ここで取り扱ったポイントは以下の通りです:
-
- GPUの設定と活用方法
- モデルを訓練モードに設定し、GPUに転送する方法
- 訓練用および検証用のデータローダーの利用
- 損失関数(criterion)と最適化手法(optimizer)の定義
- 学習ループと検証ループの実装
このコードをベースにすれば、基本的なモデル訓練はすぐに始められます。複雑なモデルや特殊な訓練条件に進む前に、まずはこの「訓練の全体像」をしっかり体感しておくことが重要です。
次のステップ
本記事は、「理論基礎編」から続く「実践基礎編」の最後の記事であり、初心者向けカテゴリの締めくくりでもあります。ここまで読んできた方は、PyTorchを使った基礎的なモデルの訓練が一通り理解できているはずです。
ここから次に進むおすすめの方向性は:
-
- 応用編(CNN、転移学習など)へ進む
- 実データを用いたプロジェクト構築に挑戦
- モデルの性能改善(学習率調整、正則化、Early Stoppingなど)
それぞれのステップに対応した記事やチュートリアルは、ブログのカテゴリ「ディープラーニング実践者編」にて順次公開していきます。
コメント