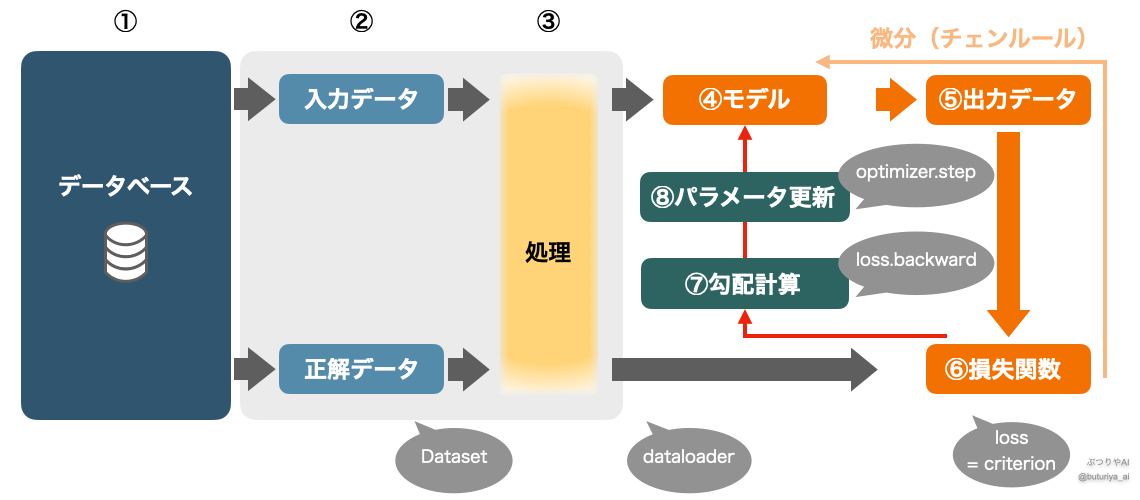
ディープラーニングでは、大量のデータを使用し、反復的な処理を通じてモデルの学習を進めていきます。このプロセス全体の大枠を、実際のコードと対応する形でまとめたのが以下の図です。本記事では、ディープラーニングの基本的な理論基礎に簡単に触れながら、実際にパソコン上で行われる処理の流れを解説していきます。具体的な実装については実装基礎編のPyTorchによる実装を御覧ください。
実装上の新しい単語などが出てきますが、まだここで気にすることはありません。各コンポーネントが短いコードで簡単にできることをなんとなく感じ取ってください。
モデルから損失まで
前処理を終えたデータは、次にモデル(図中④)に入力されます。モデルは順伝播(フォワードプロパゲーション)を通じてデータを層ごとに処理し、出力(図中⑤、output)を生成します。この出力は、dataloaderが用意した正解データ(ラベル)と比較され、損失関数(図中⑥、loss)として誤差を数値化します。
loss = criterion(output, y)ここで criterion は損失関数のインスタンスであり、y は正解データを指します。PyTorch を用いることで、このような損失関数のインスタンスを簡単に作成できます。
図中のオレンジ色で示されている部分(モデルから損失関数まで)と⑦、⑧はすべて関数としてつながっています (Tensor の自動微分)。これは⑥のlossが⑤outputの関数であり、⑤outputが④モデルの関数だからです(視覚的、数学的な説明はこちら)。
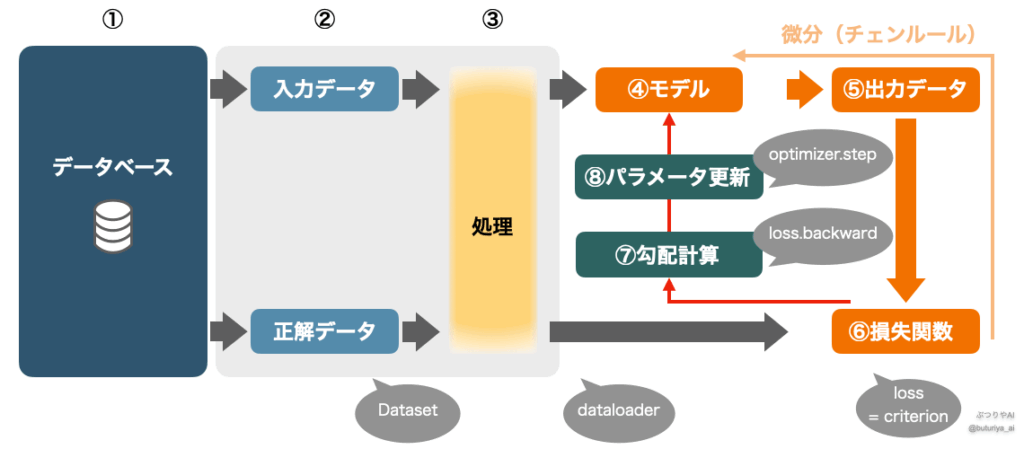
勾配計算と逆伝搬
勾配計算
損失関数をモデルのパラメータ(例えば重みw)で微分することで、損失が小さくなる方向を計算します(誤差逆伝搬法とは?勾配計算による学習の仕組み)。この処理では、チェインルールを用いて、損失関数 loss(図中⑥)から出力 output(図中⑤)、さらにモデルの各層(図中④)へと遡って微分を計算します。
loss.backward()この一行で、損失関数の各パラメータに関する勾配が自動的に計算されます。
パラメータ更新
勾配が計算されたら、次に最適化アルゴリズムをもちいてモデルのパラメータを更新します。これにより、損失関数の値が減少する方向にパラメータが調整されます。この処理は、図中⑦で示されている「勾配計算」をもとに、図中⑧の「パラメータ更新」を行うものです。
optimizer.step()ここでoptimizerは最適化アルゴリズムのインスタンスです。例えば確率的勾配降下法(SGD)は、勾配に学習率をかけた分だけパラメータを変更します。一般的には、SGD をさらに発展させた Adam とと呼ばれるものが使われます。これにより、学習の効率と安定性が向上します。
まとめ
ディープラーニングの学習アルゴリズムは、以下のプロセスを何度も繰り返すことで進行します:
- データ処理: 適宜データを読み込み、前処理を行い、ミニバッチに分割。
- モデル処理: 入力データを順伝播して出力を生成。
- 損失計算: 出力と正解データを比較して損失を求める。
- 勾配計算と逆伝播: チェインルールを使い、損失関数を微分して勾配を計算。
- パラメータ更新: 勾配に基づいてパラメータを調整。
このプロセスを繰り返し、モデルがデータを正確に予測できるように学習を進めます。各ステップを適切に理解することで、オープンソースをコピーするだけでなく、自らモデルや訓練環境を構築したり、改良してプロジェクトに最適化することができるようになります。
おすすめカテゴリー

コメント