ディープラーニングの学習プロセスでは、大量のデータを用いてモデルのパラメータを更新していきます。「誤差逆伝搬法とは?勾配計算による学習の仕組み」 で説明したように、誤差をフィードバックしながらモデルを改善していくわけですが、実際のデータ量は非常に膨大です。例えば、256×256 ピクセルの画像分類を行う場合、訓練データは通常数万枚以上 になります。この全データを一度に処理するのは、メモリ使用量や計算負荷の面で現実的ではありません。この問題を解決するのが、ミニバッチ (mini-batch) という手法です。本記事では、ミニバッチとは何か、そのメリット、さらにエポック(epoch)との関係について解説します。
ミニバッチ
ディープラーニングの学習は、順伝播(フォワードプロパゲーション)と誤差逆伝搬(バックプロパゲーション)を繰り返し行い、モデルを更新していきます。このとき、全データを一度に処理するのではなく、ミニバッチと呼ばれる小さなデータのまとまりごとに学習を行う手法を「ミニバッチ学習」といいます。
バッチサイズ
ミニバッチのサイズ(バッチサイズ)は、一般に 2 のべき乗(32, 64, 128 など)が選ばれることが多いですが、用途に応じて実験を繰り返したりしながら調整されます。
バッチサイズの特殊な例:
- バッチサイズ = 1 → オンライン学習(Stochastic Gradient Descent, SGD)
- バッチサイズ = 訓練データ全体 → フルバッチ学習(Full-Batch Gradient Descent)
通常はその中間の「ミニバッチ学習」が一般的に使われます。
直観的な理解:3次関数のフィッティング
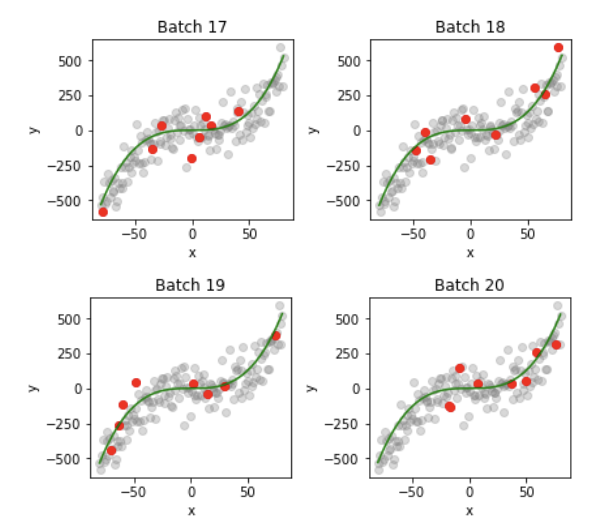
よりイメージと本質を掴むために、3次関数のフィッティングを考えてみます。以下の関数にノイズを加えたデータを160個用意し、バッチサイズ8で学習を進めてみます。
$$y = -0.001 x^3 + 0.01 x^2 – 0.1 x + 0$$
学習に使うモデルは、以下のような 3 次関数です。
$$y = a \cdot x^3 + b \cdot x^2 + c \cdot x + d$$
- 初期状態: すべての係数 \(a,b,c,d\) を0から開始 (\(y = 0\))
- 学習方法: 重複なくランダムに20ミニバッチに分ける(バッチサイズ8)

図を見ると、Batch1では初期条件 y = 0 を少しだけデータ点に近づけたような形をしています。全データを使い終わる Batch20になると、モデルがデータの傾向をよく捉えていることがわかります。しかしモデルはまだ完全にフィットされていません。ここで必要なのがエポック (epoch) です。
エポック (epoch)とは?
1エポックとは、全訓練データを 1 回すべて学習し終えることを指します。
例えば、データが 160 個あり、バッチサイズが 8 の場合、1エポックでは160 ÷ 8 = 20 回の更新 を行うことになります。
学習が十分に進んでいなければ、さらにエポックを繰り返し、モデルを改良していきます。3次関数の例でも、追加で 9 エポック(合計 10 エポック)学習したところ、データをよりよく説明できるようになりました。
ミニバッチの性質とメリット
1. メモリの節約
全データを一度に処理するフルバッチ学習は、メモリ使用量が膨大になり、実装が困難になります。ミニバッチを使えば、一度に処理するデータ量を抑えることができ、計算の効率が向上します。
2. 学習の安定化
データを 1 つずつ学習する オンライン学習では、データのばらつきにより学習が不安定になります。ミニバッチ学習は、ある程度のデータをまとめることでノイズがキャンセルするため、適度に学習を安定化できます。
3. 並列計算が可能になる
ミニバッチを用いることで、GPU の並列計算を活用し、学習速度を大幅に向上 させることができます(ミニバッチでまとめたデータの勾配を並列に計算できます)。また、DataLoaderを適切に設定することで、訓練中のデータの前処理なども CPU で並列化が可能です (「DatasetとDataLoaderの違い・使い方を図解・徹底解説」を参照)。
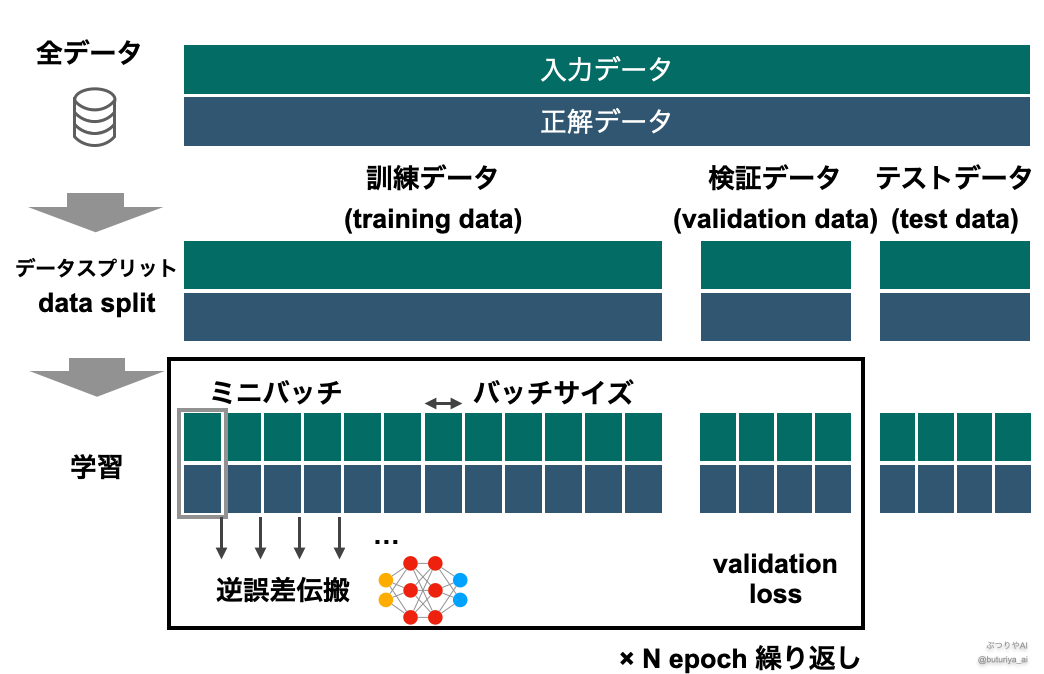
全体の学習フロー
エポックとミニバッチを組み合わせた学習の流れは次のようになります。
データを3つに分割
- 訓練データ(Training Data): モデルの学習用
- 検証データ(Validation Data): モデルの損失をモニタリング(過学習防止)
- テストデータ(Test Data): 最終評価
ミニバッチごとに学習を行う
- 訓練データを小さなミニバッチに分ける
- 1ミニバッチごとに誤差を計算し、モデルのパラメータを更新
1エポック終了後、検証データでモデルを評価
- 検証データを用いて、学習が適切に進んでいるか確認
- 過学習が進んでいれば Early Stopping(早期停止)を検討
エポックを繰り返す
- 損失(Loss)が十分に減少したら学習を終了
まとめ
ミニバッチ(mini-batch)とは?
- 全データを一度に処理せず、小さなまとまりごとに学習する手法
- メモリ節約、学習の安定化、並列計算による高速化のメリットがある
エポック(epoch)とは?
- 訓練データをすべて1回学習し終えること
- 通常、複数エポックを繰り返し学習させる
実際の学習プロセス
- 訓練データ → ミニバッチで学習
- 1エポックごとに検証データで精度チェック
- 損失が十分に減少したら学習終了
おすすめカテゴリー

コメント