私は初めて PyTorch を学んだ時、Dataset と DataLoader の違いが何なのか、それぞれの役割がどう分かれているのかがよくわからずに混乱しました。ここではそれぞれが互いにどういう関係で何をするものなのかわかるように、
- 前半ではイラストとともに機能のイメージを、
- 後半では実装とともにクラスやメソッドの仕様を、
- さらにtransformsとともにコードとカスタマイズの仕方を、
説明します。少し長くなりますが、ぜひこれらはセットでしっかりと理解してください。
<この記事で扱う主要なモジュール・ライブラリ一覧>
import torch
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transforms<関連記事>
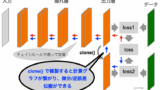
DatasetとDataLoaderの役割
ディープラーニングでは、大量のデータを学習に使用します。しかし何 GB もある大量のデータを直接メモリに読み込むのは非現実的なので、ディスクから少しずつロードする仕組みが必要です。データの準備は Dataset と DataLoader の2つの機能に分解されます。
Datasetとは?

“すぐに使える状態”のデータセット
Dataset (図右:青) は PyTorch であらかじめ用意されているクラスです。データ番号を指定すると対応したデータを返す (図左:水色) ので、外からは文字通りデータの集まり、「データセット」のように見えます。しかし実際には、指定された番号に対応した生データ(図右)をハードディスクから読み込み、所定の処理をしてから返す、ということをしています。データ番号を指定した段階では学習にすぐ使えるデータ(図左)がメモリ上にあるわけではなく、必要な生データをその都度ロードして処理するのです。この仕組みにより、大規模なデータでも効率よく管理できます。
なぜデータ処理が必要?
HDD に保存されているデータは、 numpy.ndarray や PIL.Image、医療画像なら DICOM 形式など、用途に応じて様々です。これらのデータは、PyTorch の計算に適した形式に統一する必要があります。特に、誤差逆伝搬(誤差逆伝搬法とは?勾配計算による学習の仕組み)時に自動微分を利用するため、Tensor という特別なデータ構造に変換します。また、学習中にランダムな回転・反転やノイズの付加などのデータ拡張(augmentation)を行い、データの多様性を増やすことも重要です。こういった変換を Dataset 内で行います。
Tensor は Numpy の ndarray に似た多次元配列ですが、決定的な違いがあります。それは、
Tensorは適切に設定をすれば自動微分が可能になることです。ニューラルネットワークはノードごとに関数が積み重なっています (ニューラルネットワークの多層化(MLP)) が、そういった複雑な構造でも、ノードごとの勾配を自動で計算できます。そのため、ディープラーニングでは、入力/正解データを Tensor に変換するのです。
DataLoaderとは?

DataLoader も PyTorch で用意されているクラスです。DataLoader (図上:緑) は、Dataset (図上:青) からデータをバッチ単位で取得し、シャッフルや並列処理を行う機能を持ちます。これにより、学習させるデータの順番を変えたり、ミニバッチごとに素早く並列でデータを取得することができます。データをロードしているのは Dataset じゃないか、と思われるかもしれませんが、先程の説明の通り、 Dataset は実質的にはデータの集合として考えられ、DataLoader はそこからデータをバッチ単位で “ロード” することになります。バッチごとに取り出されたデータはその都度パラメータの更新に使われ(図下)、すべてのバッチで学習が終わると1エポックとなります (ミニバッチとエポック)。
Datasetの使い方
Datasetのメソッド
torch.utils.data.Dataset は PyTorch に組み込まれている親クラスであり、これを継承してカスタムデータセットを作成できます。__init__, __len__, __getitem__ の3つの特殊メソッドを定義することで、データセットとして動作します。メソッドはクラスの中で定義された関数のことで、クラスから生成されたインスタンスから呼び出せます。そのなかでも特に __init__、__len__、__getitem__ という名前のメソッドは Python の仕様で決まっている特殊メソッドと呼ばれ、それぞれ特殊な機能をインスタンスに付与できます。これらはすべて、カスタマイズするうえでとても重要になります。個々の役割とともに、それぞれの機能を具体的に見てみましょう。
特殊メソッド:__init__
Dataset クラスのインスタンスが作成されるときに、特殊メソッド __init__ の性質として Python に自動的に呼び出されます。これによって、インスタンスを使う上で必要な変数の初期化や計算を最初にできます。
特殊メソッド:__len__
特殊メソッド __len__ を定義すると、Python の仕様により、len(obj) で obj.__len__() が呼び出されます。そして __len__() はデータセットのサイズを返すように定義されます。したがって、Dataset のインスタンスはまさに文字通り”データセット(のリスト)”かのように振る舞います。
l = [0, 1, 2]
print(len(l)) # リスト l のサイズ 3 が出力される
dataset = MyDataset()
print(len(dataset)) # "dataset" のサイズが出力される特殊メソッド:__getitem__
特殊メソッド __getitem__ を定義すると、Python の仕様により、obj[idx] (idx は 0、1 などの整数) によりobj.__getitem__(idx) が呼び出されます。これによりインデックスでデータにアクセスできるようになり、やはり Dataset のインスタンスは実際に (処理済みの) データを要素として持つリストかのように振る舞います。
l = [0, 1, 2]
print(l[0]) # リスト l の最初の要素 0 が出力される
dataset = MyDataset()
print(dataset[0]) # "dataset" の最初の要素が出力されるDatasetのカスタマイズと実装
Dataset はデフォルトの Dataset を雛形に、自分の学習に合うように変更します (参照:torch.utils.data )。これを継承といいます。あまり難しく考えず、下のコードの MyDataset(Dataset) となっている部分で Dataset を引き継いで、新しく MyDataset を定義している、と考えてください。
以下にわかりやすい範囲で実用的な Dataset を書きました。__init__ では、インプットデータのフルパスのリスト input_paths と、正解データのリスト self.label_data を初期化します。正解のラベルデータは容量が小さいと思われるので、__init__ですべてロードしています。transform は後ほど説明しますが、データ処理やデータ拡張 (augmentation) の処理をまとめたものです。__getitem__ では、idx 番目の input/label データを取得、 self.transform で前処理をしてからまとめて返します。
from torch.utils.data import Dataset
import numpy as np
class MyDataset(Dataset):
def __init__(self, input_paths, label_path, transform=None):
self.input_paths = input_paths
self.label_data = np.load(label_path)
self.transform = transform
def __len__(self):
return len(self.input_paths)
def __getitem__(self, idx):
input_data = np.load(self.input_paths[idx])
label_data = self.label_data[idx]
if self.transform:
input_data = self.transform(input_data)
return input_data, label_dataDataset は 学習の際は直接は使いません。ただし、データが正しく読み込めているか、あるいはデータの前処理が正しく行われているかを確認する時などに単体で使います。以下の例だと、Dataset の input_data は画像データ、label_data は 画像のラベルということになります。
import matplotlib.pyplot as plt
dataset = MyDataset(input_paths, label_paths)
image, label = dataset[0]
plt.imshow(image)
plt.title(label)Datasetでのtransformsの活用
transforms
Dataset の中での様々な前処理は直接 __getitem__ の中に書くこともできますが、PyTorch のモジュール transforms を使うことで、様々な処理をたった1行でスマートに実装することができます。基本的には numpy ではなく tensor を、画像処理では PIL 画像を処理できます。ほしい処理があったら torchvision.transforms の公式ドキュメント を確認し、引数や処理の内容を把握してください。それでもほしい処理がない場合は、自作、カスタマイズも簡単にできますが、ここでは割愛させていただきます。
以下、ごく一部ですが、transforms をいくつか紹介します。
transforms.ToTensor()(PILイメージ, numpy を tensor に変換)transforms.Normalize()(データの標準化)transforms.Resize()(画像のマトリックスサイズの変更)transforms.RandomHorizontalFlip()(ランダムに画像の反転)transforms.RandomRotation()(ランダムに画像を回転)
上に上げたようなtorchvision.transforms に含まれる Transform クラスはすべて __call__ を持っており、インスタンスを関数のように使うことができます。ただし、transforms.functional の関数(例: F.resize, F.to_tensor)は __call__ を持たず、以下で説明する Compose でまとめられないですが、直接 torch.Tensor に適用できるため、データの前処理をカスタマイズしたい場合に便利です。
import torch
import torchvision.transforms as transforms
import numpy as np
x = np.random.rand(128, 128) # 仮の画像データ
totensor = transforms.ToTensor() # インスタンスを作成
x = totensor(x) # 関数のようにデータを1行で処理。Numpy Array から Tensor に変換transforms.Compose
transforms は1つのクラス(関数)で1つの処理をしますが、普通は様々な処理が必要です。そこで、Compose のインスタンスで transforms をまとめ、それを Dataset に渡します。まとめたインスタンスは Compose を使うことで順番にすべて適用されます。
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
])
image_transformed = transform(image) # すべての変換を連続適用一般的に、Compose で Transform クラスをまとめ、それを Dataset に入れ、その Dataset で DataLoader を作ります。
DataLoaderの使い方
DataLoaderの基本的な引数
DataLoader を作る際は、かならず Dataset を引数として渡します。以下、その他の基本的な引数をまとめます。
- batch_size: ミニバッチのサイズ
- shuffle: 読み込み時にデータの順番をシャッフル
- num_workers: 並列処理に使う CPU のスレッド数
- pin_memory: GPU に転送する際の最適化
- drop_last: 全データをミニバッチ単位で割り切れない場合に、最後の小さいバッチを無視
損失関数の形はデータによって変わります。したがって、ミニバッチ毎に区切った勾配計算は、データの選び方によります。そこでエポック毎にランダムにデータの選び方を変えるのが shuffle です。
DataLoader でのデータ読み込みや処理は CPU で行われます。したがって、せっかく高価な GPU を使っても、ここがボトルネックになってしまう可能性もあります。これを防ぐためにも、num_workers でデータローディングの並列処理に使うプロセス数を指定します。CPU のコア数以下で設定し、適切な値を試しながら調整してください。
DataLoaderの実装と使い方
以下、transform を利用した Dataset のインスタンスを使ったときの例です。DataLoader に必要な引数をいれるだけで DataLoader を使えます。
from torch.utils.data import Dataset, DataLoader
# Dataset
# ここで MyDataset を定義 (省略)
# transforms.Compose の定義
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(), # () を追加
transforms.Normalize(mean=[100], std=[10])
])
# Dataset のインスタンスを作成
dataset = MyDataset(transform=transform)
# DataLoaderの作成
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
num_workers=num_workers,
pin_memory=pin_memory
)実際の学習での使用は簡単です。DataLoader は Pythonの iterable と呼ばれるもので、リストなどと同様にfor ループで順番に要素を取り出せます。この for ループ内でミニバッチごとの推論と誤差逆伝搬が行われ、1つのエポックとなります。
for batch in dataloader:
x, y = batchまとめ
本記事では、Dataset と DataLoader の役割と使い方について詳しく解説しました。
- Dataset
torch.utils.data.Datasetを継承してカスタマイズすることで、オリジナルのデータセットを作成。__init__でデータのリストや前処理を設定。__len__でデータセットの総数を取得可能。__getitem__でインデックス指定によるデータ取得を実装。
- DataLoader
Datasetからデータをバッチごとに取得し、シャッフルや並列処理を行う。batch_sizeを指定することで、ミニバッチ単位で学習を実施。num_workersを増やすことで、データローディングを並列化し高速化が可能。pin_memory=TrueとGPU にデータ転送する際の速度を最適化。
- transforms の活用
transforms.Composeで複数の前処理をまとめて適用。torchvision.transformsにあるResize,ToTensor,Normalizeなどを活用すると、データの前処理を簡単に記述可能。transforms.functionalはComposeには入れられないが、個別のデータに直接適用可。
- 実際の実装
Datasetを作成し、それをDataLoaderに渡すことで、学習のためのデータ処理が簡単にできる。for batch in dataloader:等とすることで、ミニバッチごとにデータを取得し、学習ループを回せる。
本記事の内容を理解すれば、PyTorch でのデータ管理の基本を押さえることができ、スムーズにモデルの学習を進められます。
最後に、学習全体の概観について復習したい方はこちらをご参照ください。
おすすめカテゴリー

コメント