PyTorch でモデルを構築する場合、主に以下の5つを使います。
- Class:
torch.nn.Module - Class: レイヤー (
torch.nn.ReLUなど) - Class:
torch.nn.Sequential - Class:
torch.nn.ModuleList - func:
torch.nn.functional
多くの場合、nn.Module をベースにモデルを自作します。このとき、nn.Module を継承したサブクラスであるレイヤー、nn.Sequential、nn.ModuleList などを使ってモデルの構造を作ります。また、nn.functional にある関数も補助的に使用されます。
<概要>
本記事では上記の構成要素と nn.functional の関係や使い方をコードとともにまとめ、実際にニューラルネットワークのモデルを自作するための基礎を説明します。
<この記事で扱う主要なモジュール・ライブラリ一覧>
import torch
import torch.nn as nn # 一般的に"nn"としてインポートされる
import torch.nn.functional as F # 一般的に"F"という名前でインポートされる
from collections import OrderedDict<関連記事>
モデルの作り方 ― nn.Module の思想と構造
PyTorch でニューラルネットワークのモデルを構築する場合、「モデル」とは モジュールクラス(のインスタンス)を作ることを意味します。
nn.Linear などのレイヤーや nn.Sequential は単体でもモデルとして使用可能なモジュールですが、複雑で実用的なモデルを作る際には、自分で基底クラスである nn.Module を継承してモジュールクラスを定義する必要があります。
モジュールはレイヤーを最小単位とし、互いにネストすることでツリー構造を作ることができます。よくある構成としては、自作クラス内でレイヤー、nn.Sequential や nn.ModuleList を使用するというものです。
forward メソッドを定義したモジュール(図中オレンジ枠)は、インスタンスがそのまま「関数」として動作するようになります。こうした forward() をもつモジュールはすべて、ニューラルネットワークのモデルとして使用できます。一方、nn.ModuleList は forward を持たず、単体ではモデルとしては機能しません。
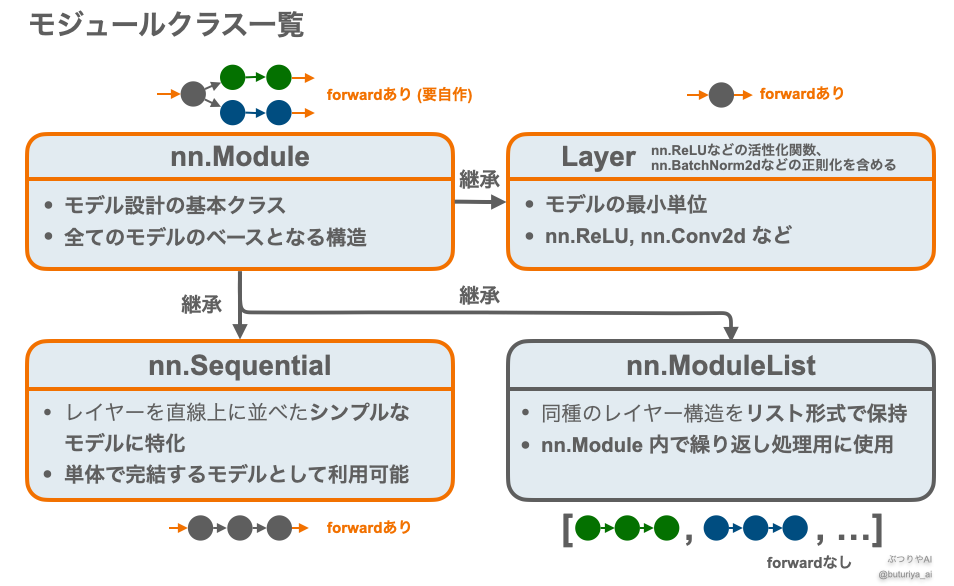
モデルの最小単位 ― レイヤー
nn.Module を継承したモジュールクラスとして、「レイヤー」と呼ばれるものが torch.nn (公式ページ)にあらかじめ準備されています。
一般的には、学習可能なパラメータを持つ線形結合(nn.Linear)や畳み込み(nn.Conv2d)などを指しますが、ここでは活性化関数(nn.ReLU、nn.Sigmoid…)や正則化(nn.BatchNorm2d など)も含めて、広義の「レイヤー」として扱います。
これらはニューラルネットワークにおける最も基本的な構成要素です。
# torch.nnをnnとしてインポートする ("nn"でtorch.nnを参照できる)
import torch.nn as nn
net = nn.Linear(2, 4)上の例では、2次元の入力テンソルから4次元の線形結合出力を得る nn.Linear を使用しています。
このようなレイヤーのインスタンスは、パラメータ(重み・バイアス)を内部に持ち、初期化された状態で順伝播できるようになります。
最も簡単なモデル構築 ― nn.Sequential
nn.Sequential (公式ページ)は nn.Module を継承したサブクラスです。Sequential 自体は単なる入れ物で、必要なレイヤーのインスタンスを順番に入れるだけで、それらを1本につなげた「Sequential(逐次的)」なモデル(上図中のイラスト参照)を作ることができます。
ただし、nn.Linear などのレイヤーは入力・出力サイズの指定が必要なので、各レイヤー間で形状が一致するように設計する必要があります。
具体的な作り方は、以下のいずれでも問題ありません。
Sequentialの作り方1 ― レイヤーのインスタンスを直接並べる
import torch.nn as nn
# Sequentialでモデルを定義。レイヤーのインスタンスを並べるだけ。
net = nn.Sequential(
nn.Linear(20, 256),
nn.ReLU(),
nn.Linear(256, 10),
nn.ReLU(),
)
print(net)出力例:
Sequential(
(0): Linear(in_features=20, out_features=256, bias=True)
(1): ReLU()
(2): Linear(in_features=256, out_features=10, bias=True)
(3): ReLU()
)この例では、入力が20次元のベクトルで、それを256ノードの層→ReLU→10ノードの層→ReLUと通す構造になります。パラメータがランダムなため、出力も以下のように適当な値になります。
import torch
x = torch.ones(20)
predict = net(x)
print(predict)
# 出力例(ランダムな初期化による)
# tensor([0.0000, 0.2197, 0.0000, 0.0000, 0.0000, 0.0000, 0.1862, 0.2169, 0.0000, 0.0000], grad_fn=)Sequentialの作り方2 ― リストをアンパック
レイヤーをリストに入れ、アンパック(*)して渡す方法もあります。
import torch.nn as nn
layer_block = [nn.Linear(5, 256), nn.ReLU(), nn.Linear(256, 5), nn.ReLU()]
net = nn.Sequential(*layer_block)Sequentialの作り方3 ― OrderedDictを使って名前を付ける
OrderedDict を使うと、各レイヤーに明示的な名前をつけることができます。先ほどは自動的に (0), (1), … と番号が振られましたが、代わりに、'linear_in' や 'relu_in' などと名前をつけて管理できます。
from collections import OrderedDict
import torch.nn as nn
layer_block = OrderedDict([
('linear_in', nn.Linear(5, 256)),
('relu_in', nn.ReLU()),
('linear_out', nn.Linear(256, 5)),
('relu_out', nn.ReLU())
])
net = nn.Sequential(layer_block)モデル設計の本質 ― nn.Moduleを継承
nn.Moduleとは?基底クラスの役割
nn.Module(公式ページ)自体は、ニューラルネットワークのモデル構築・訓練・推論などに共通する機能を持った、抽象的な基底クラスです。
このままではモデルとして使用できないため、具体的なモデルを構築するには、次に説明するようにnn.Module を継承し、レイヤーや他のモジュールを組み合わせて定義する必要があります。自由度が高く、基本的にどんなモデルでも表現可能です。
レイヤーの定義と forward
nn.Module を継承したクラスでは、以下の2つのメソッドを定義するのが基本です:
__init__():クラスの初期化(レイヤー定義)forward():順伝播処理(入力→出力の変換)
__init__() は特殊メソッドで、インスタンス生成時に呼ばれます。ここでレイヤーや Sequential、ModuleList などを定義しておきます。
先頭に記述する super().__init__() は、親クラスである nn.Module の初期化処理を呼び出すため、必ず必要です。
一方 forward() には、入力をどのように処理して出力するかのロジックを記述します。これは Python の特殊メソッド __call__() によって内部的に呼び出され、インスタンスが「関数のように使える」ようになります。
# https://pytorch.org/docs/stable/generated/torch.nn.Module.html
import torch.nn as nn
import torch.nn.functional as F
class MyModel(nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 3)
self.conv2 = nn.Conv2d(20, 20, 3)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))nn.Moduleの諸機能
学習・評価モードの切り替え:.train() / .eval()
学習時と推論時では、Dropout や BatchNorm など一部のレイヤーの挙動が異なる設計なため、.train() / .eval() メソッドでモードを切り替える必要があります。
net = MyModel()
# 学習モード
net.train()
# 推論モード
net.eval()デバイス管理:.cuda() / .cpu()
モデルのパラメータも Tensor と同様に GPU / CPU 間で移動させることができます。以下のように指定可能です:
net = MyModel()
# GPUのIDを指定して移動
net.cuda(0)
# デバイスオブジェクトで指定
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
net.to(device)モデルの保存とロード:.state_dict() / .load_state_dict()
公式チュートリアルにあるように、PyTorchでは、モデルのパラメータ(重みやバイアス)を保存・復元するために state_dict() / load_state_dict() が提供されています。
これにより、モデルの構造ではなく、学習の進行状態(チェックポイント)としてパラメータだけを効率的に保存できます。
保存されたパラメータを使用するには、まず訓練時と同じ構造の nn.Module インスタンスを再生成し、その後 load_state_dict() を呼び出して復元します。
保存:torch.save と state_dict()
torch.save(net.state_dict(), 'model.pth') # 保存先ファイル名state_dict() によって、モデルのすべての学習可能パラメータが辞書形式で取得され、.pth という形式で保存されます。
ロード:load_state_dict()
net = MyModel() # モデル構造を再生成
net.load_state_dict(torch.load('model.pth')) # パラメータを読み込みモデル構造が保存時と一致している必要があるため、モデルのインスタンスを生成してから読み込みを行います。
実践的な nn.Module の作り方
モジュールは互いにネスト(入れ子構造)にできます。nn.Module を継承したクラスの中で nn.Sequential や nn.ModuleList を使えるのはもちろん、自作したモジュール同士をさらに他のモジュールの中で使うこともできます。
そのため構造の組み合わせは事実上無限にありますが、ここでは代表的な構造として、nn.Module の中で Sequential や ModuleList を利用する例を紹介します。
nn.Module + nn.Sequential
Sequential はレイヤーを順番に並べて接続するための簡便な仕組みです。以下は MLP(Multilayer Perceptron) を nn.Module と nn.Sequential を組み合わせて構築した例です。
この例では以下の3つのレイヤーブロックを使っています:
self.input_layer: 入力ノード → 隠れ層ノードself.hidden_layers: 同じサイズの隠れ層をnum_layers回繰り返す(Sequentialで実装)self.output_layer: 隠れ層ノード → 出力ノード
import torch
import torch.nn as nn
import torch.nn.functional as F
class MLP(nn.Module):
def __init__(self, input_dim=64, hidden_dim=64, num_layers=5, output_dim=1):
super().__init__()
self.input_layer = nn.Linear(input_dim, hidden_dim)
layers = []
for _ in range(num_layers):
layers.append(nn.Linear(hidden_dim, hidden_dim))
layers.append(nn.ReLU())
self.hidden_layers = nn.Sequential(*layers)
self.output_layer = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = F.relu(self.input_layer(x))
x = self.hidden_layers(x)
return self.output_layer(x)nn.Module + nn.ModuleList
ModuleList(公式)は、nn.Module のリストのように使えるコンテナです。
Sequential はレイヤーをつなげて1つの大きなモジュールにするのに対して、ModuleList は個別のレイヤーをリスト形式で保持します。そのため forward() の中で、ループを用いて手動で処理する必要があります。
class MLP(nn.Module):
def __init__(self, input_dim=64, hidden_dim=64, num_layers=5, output_dim=1):
super().__init__()
self.input_layer = nn.Linear(input_dim, hidden_dim)
self.hidden_layers = nn.ModuleList([
nn.Linear(hidden_dim, hidden_dim) for _ in range(num_layers)
])
self.output_layer = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = F.relu(self.input_layer(x))
for layer in self.hidden_layers:
x = F.relu(layer(x))
return self.output_layer(x)先ほどとモデルは全く同じですが、 ModuleList を使えば forward() 中で各層に対して個別に処理を加えたり、途中の出力を取り出す、分岐させるなどといった、柔軟な操作が可能になります。これは Sequential にはない利点です。
nn.Module + nn.functional
nn.functional には、パラメータを持たない演算関数が多数含まれています(例:F.relu、F.softmax など)。
一見すると F.linear や F.conv2d のようにパラメータを含むように見える関数もありますが、これらは「学習用のパラメータ」ではなく、引数として外部から渡す形式になります。
つまり nn.functional は、学習用ではない固定的された演算を手動で設計する場合などに使用します。
まとめ
- nn.Module は PyTorch モデル構築の基底クラスで、全てのモデルの土台。
- レイヤー(nn.Linear や nn.ReLU など)は nn.Module を継承した最小単位。
- nn.Sequential は直列構造に特化し、最も簡単に使えるモデル構築法。
- nn.ModuleList は柔軟な繰り返しや構造操作に強く、for文と併用される。
- nn.functional は演算関数の集合で、設計上の固定処理や補助的な役割に活用。
- forward() を持つモジュールは関数のように使え、モデルとして使用可能。
- モジュールは自由にネスト可能で、複雑な構造でも柔軟に対応できる。
コメント