初心者がモデルの作成・訓練を体験するには、MNIST と呼ばれる手書き数字のデータセットと Keras とよばれるライブラリが適しています。本記事のゴールは
- ディープラーニングは「こんなものなのか」と実感する
- 様々な概念や手法を一通り俯瞰して感覚を掴む
です。ネットに繋がっていれば Google アカウント (Google Colab) 一つで、今すぐに GPU でディープラーニングを実践できてしまいます。 所要時間はおよそ10 分。それでは始めてみましょう!
本記事のサンプルコードは GitHub で公開しています。Google Colab で直接開くこともできます。
*ノートブックに説明や出力結果を加えたものが git にあります。ぜひご活用ください。都度説明はしますが、詳しい Google Colab の導入はこちらを御覧ください。
<本記事で使用する主要なモジュール・ライブラリ>import tensorflow as tf
# mnistデータ
from tensorflow.keras.datasets import mnist
# keras
from tensorflow import keras
from tensorflow.keras.models import Sequential # モデルの入れ物
from tensorflow.keras.layers import Dense, Activation # FCN, 活性化関数
from tensorflow.keras.optimizers import SGD # 最適化アルゴリズム
from tensorflow.keras.utils import to_categorical # one-hot-encoding
import numpy as np
import matplotlib.pyplot as pltMNIST データセットの準備と前処理
TensorFlowとKerasのインポート
まずはディープラーニングのライブラリ、TensorFlow と、その高レベル API である Keras から、必要なものをあらかじめインポートしておきます。プログラミングは基本的に、英語で素直に書かれていることが多いです。例えば以下にある from A import B はそのまま直訳できて、「 A の中から B を持ってきなさい」という命令文です。インポートしたものについては、後ほど使うときに説明します。
import numpy as np
import matplotlib.pyplot as plt
# tensorflowをインポート
import tensorflow as tf
# Kerasからモデル関連のインポート
from tensorflow.keras.models import Sequential # モデルの入れ物
from tensorflow.keras.layers import Dense, Activation # FCN, 活性化関数
# Kerasからトレーニング関連のインポート
from tensorflow.keras.optimizers import SGD # 最適化アルゴリズム
from tensorflow.keras.utils import to_categorical # one-hot-encodingMNISTデータセットのロードと可視化
データは以下のコードでロードし、変数に格納します。x_ から始まる量がモデルにインプットする 28 x 28 ピクセルの画像データで、shape は (サンプル数, 28, 28) です。y_ から始まる量は正解ラベルで、画像に描かれている数字の 整数値(0〜9)が格納された 1次元の配列 、shape は (サンプル数, ) です。_train で終わるデータは訓練用、_test で終わるデータは、訓練したあとにモデルの(汎化)性能を評価するためのデータです。
from tensorflow.keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()matplotlibでプロットすると、データは以下のようになります(詳細は GitHub の ノートブック参照)。

データの前処理(ベクトル化 & 正規化)
今回はシンプルな全結合ニューラルネットワーク(FCN; Fully Connected Network)を使います。そのため、入力は1次元のベクトルでなければいけません。そこで、以下の図のように、MNIST 画像を1次元のベクトルに変換します。
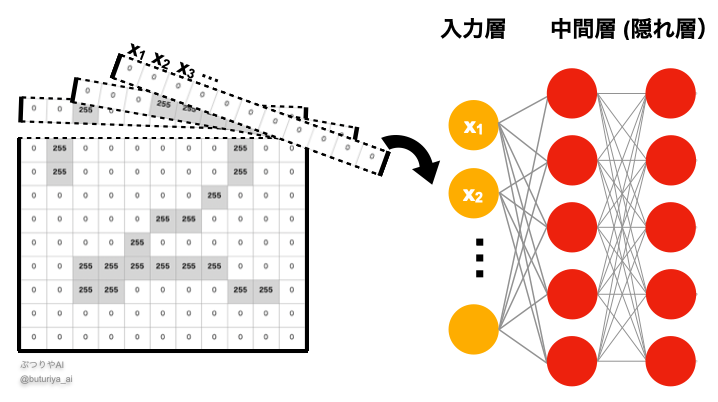
シンプルに reshape で形を変えます。もともと28 x 28 ピクセルのデータなので、1つ1つのデータは28 x 28 = 784 次元のベクトルになり、例えば x_train_flattened の shape は (60000, 784) になります。ついでに型を float32 に、ピクセル値のレンジを 0 ~ 1 に正規化しています。
x_train_flattened = x_train.reshape(x_train.shape[0],-1).astype('float32') / 255
x_test_flattened = x_test.reshape(x_test.shape[0], -1).astype('float32') / 255
num_features = x_train_flattened.shape[1]one-hot encoding(ラベルの変換)
今回のような分類を行う場合、入力画像に書かれた数字が 0 ~ 9 それぞれの数字である確率を出力にします。したがって、1つの画像に対して、出力は 0, 1, 2, … 9 それぞれの値の確率になり、10 次元のベクトルになります。もし入力画像に 0 と書かれていたら正解は 0 の確率が 1, その他の数字の確率が 0 なので [1, 0, …, 0]、もし 9 と書かれていたら 9 の確率が 1 でそれ以外は 0 なので [0, …, 0, 1]、といった具合になります。
ロードした正解データは正解ラベル (正解の数字)が書かれているので、ラベルの値を 10 次元のベクトルに直す必要があります。こういった作業はよく行われ、例えば画像の中を物体事に塗り分けるセグメンテーションでは、ピクセル事に物体 A の確率、物体 B も確率 … を出力します。したがって以下のように、そのための関数があらかじめ用意されています。 これによって、y_train の shapeが (60000,) だったのが、y_train_one_hot は (60000, 10) になります
y_train_one_hot = to_categorical(y_train)
y_test_one_hot = to_categorical(y_test)KerasでFCNモデルを構築
全結合ニューラルネットワーク(FCN)
以下では Keras でモデルを作成します。まずはクラス Sequential() (公式リンク) でモデルのインスタンス model を作ります。これがモデルの本体であり、箱のようなものです。Sequential のメソッド add() を使って、レイヤーを順番に追加していきます。まず最初に、全結合ニューラルネットワーク Dense (公式リンク) を追加します。これにより、入力層から中間層へ、ウェイトをかけてバイアスを足すノードができます。さらにつながったノード先で値を活性化関数に通すため、ReLU 関数の Activation (’relu’, 公式リンク) を追加します。出力層は 10次元のベクトルなので、Dense(num_classes) で 10個のノードにつなげ、出力がそれぞれのクラスで確率になるように softmax という活性化関数につなげます。詳細は述べませんが、softmax は各クラスで 0 ~ 1 の数字を出力し、すべてのクラスを足し合わせると 1 になります。
model = Sequential()
# モデルのパラメーター
num_hidden_units = 128 # number of hidden layers
num_classes = 10 # number of labels (0 ~ 9)
# Kerasでニューラルネットワーク(順伝播型)を作る
model = Sequential() # モデルの入れ物を作成
# 1つ目の全結合層(隠れ層)
model.add(Dense(num_hidden_units, input_dim=num_features))
# → 入力層(input_dim=num_features)から隠れ層へつなぐ
# → num_hidden_units は隠れ層のニューロンの数
model.add(Activation('relu')) # 活性化関数 ReLUを追加
# 2つ目の全結合層(出力層)
model.add(Dense(num_classes))
# → 隠れ層から出力層へつなぐ
# → num_classes は分類クラス数(例:3クラスならnum_classes=3)
model.add(Activation('softmax'))
# → 出力を確率に変換(各クラスの確率を0〜1にし、合計が1になるようにする)ハイパーパラメータの設定(学習の準備)
訓練の仕方には様々なバリエーションがあります。設計自体も多種多様で、将来、みなさんもそれぞれいろんな工夫をすることになりますが、そのうち特にパラメータで表現できるようなものを「ハイパーパラメータ」と呼びます。以下で設定するのは、どれも基本的なものになります。
num_epochs = 10 # number of epoch
batch_size = 128 # number of mini-batch
verbose = 1 # verbose level
validation_split = 0.2 # ratio to split train data into validation data
# 最適化アルゴリズム
optimizer = SGD() # optimizerエポック数 (num_epochs)、バッチ数 (batch_size)、検証データ (validation_split) については「ミニバッチとエポック」、最適化アルゴリズム (optimizer) については「損失関数ー勾配降下法と最適化のしくみ」や「ニューラルネットワークの最適化を視覚化する」、隠れ層については「ニューラルネットワークの層構造とその役割」を参照ください。ここでは単純な SGD (Gradient descent (with momentum) optimizer : 確率的勾配降下法、公式リンクはこちら、損失関数ー勾配降下法と最適化のしくみ)を使用しますが、実際のディープラーニングでは Adam (公式リンク) が広く使われています。
モデルのコンパイル(学習の準備)
最後に、Sequential のメソッドである compile でモデルをコンパイルし、訓練ができる状態にします。損失関数は softmax による分類問題とセットで使われる categorical_crossentropy (交差エントロピー)と呼ばれるものを使います。metrics で accuracy とすることで、学習中、正解率をモニタリングすることができます。
model.compile(loss='categorical_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])ここでメソッド summary() を使うと、以下のような結果が出てきます。1つ目の dense でパラメータが100,480とあります。なぜこの数字になるのでしょうか?まず、インプットが28 * 28 = 784 個の数字です。そしてそれらが 128個のノードにつながるので、784 * 128 = 100,352 個の組み合わせがあり、それらすべてに異なる重み w が割り当てられます。さらに 128 個のノードにあるバイアス 128個を足すと、100,480になります。ぜひ dense_1 のパラメータ数も計算して確かめてみてください。

KerasでMNISTモデルを学習・評価
Kerasでモデルを訓練(model.fit)
訓練は、Sequential のメソッド fit でできます。
history = model.fit(x_train_flattened, y_train_one_hot,
batch_size=batch_size,
epochs=num_epochs,
verbose=verbose,
validation_split=validation_split)学習曲線の可視化(loss & accuracy)
Sequentialfit の返り値は history オブジェクトと呼ばれ、エポックごとの損失関数の値やコンパイル時に指定した metrics (ここでは accuracy) が以下のように格納されています。
plt.plot(history.history["loss"], label="train")
plt.plot(history.history["val_loss"], label="test")
plt.plot(history.history["accuracy"], label="train")
plt.plot(history.history["val_accuracy"], label="test")
これを見ると、今回のエポック数 10 はまだ足りず、もっと増やす必要がありそうです。
モデルの評価(テストデータの精度)
ディープラーニングに限らず、機械学習では、学習に使ったデータセットとは独立したテストデータで、学習がどれくらい上手くできたか、モデルが十分に汎化性能をもつかを確認します。Sequential のメソッド、evaluate を使って、損失の値と正解率は以下のように計算できます。
# test the trained model
score = model.evaluate(x_test_flattened, y_test_one_hot, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])予測結果の可視化(手書き数字の分類)
さらに具体的に、どのような出力が得られたかも見てみましょう。
plt.plot(prediction[0])
plt.title(f'true label: {y_test[0]}')
plt.xlabel('labels')
plt.ylabel('probability')
plt.show()これにより、1 番目のテストデータが 0 ~ 9 である確率が以下のようにプロットされます。label が 2 の確率がほぼ 1 (100%) 、それ以外がほぼ 0 で、正解ラベルの 2 を予測できている事がわかります。

Keras+MNISTの学習のまとめ
大まかな流れを復習します:
- データを準備する (今回はすべて変数に格納)
- データの前処理(one-hot encoding)
- ハイパーパラメータの設定
- モデルの構築 (
Sequential,model.add,model.compile,model.summary) - 学習(
model.fit) - テストデータでパフォーマンス(正解率、損失関数)を評価 (model.evaluate)
いかがだったでしょうか? Kerasで Sequential() を使用し、モデルのインスタンスを作ると、その後必要な計算や学習(フィッティング)等、すべてがメソッドでできてしまいました。今回は非常に簡単な中間層が1つの FCN を作りましたが、これでもかなりの正解率 (90%以上) になります。ディープラーニングを使わずに同じことをしようとしたら、相当複雑なアルゴリズムを作らなければなりません。
今回使ったハイパーパラメータの数字には特別に意味があるわけではありません。今すぐにColabでノートブックを開き、CPU と GPU、エポック数 (num_epochs) や隠れ層のノード数 (num_hidden_units) などのハイパーパラメータ、隠れ層のレイヤー数などを変えてみて、結果や学習速度がどのように変化するかを観察してみてください。
おすすめカテゴリー

コメント