<概要>
Perceptual Lossはノイズ除去などにおいて、人間が認識する、画像に含まれる構造に着目して、より現実的に意味のある学習を可能にします。
本記事では、Perceptual Lossの大まかな原理、中間層から得られる feature map(特徴マップ)の様子、VGG16を用いた実装から応用例、より効果を上げるための Tips まで説明します。
Perceptual Loss に至る背景
従来の画像比較の定量化
教師あり学習で画像処理を行う場合、入力画像からターゲットとなる画像を出力するように訓練するのが一般的です。その際、出力画像がターゲットと等しくなることを目的に、ピクセルごとの誤差を足し上げた値、MSE(Mean Square Error)が損失関数としてよく用いられます。
AIの現実的な限界
MSEがテストデータで限りなく0に近づくことが理想ですが、ノイズ除去や超解像などの応用では、完全に期待通りの画像を出力するのは原理的に不可能です。つまり、学習結果が不完全なりに、どのように正解に近づけるかが重要になります。
直感的な画像比較の定量化
MSEによる訓練では、数値的な誤差が小さくても、人間が見て「不自然」と感じる構造の誤差が残ることが多くあります。それはMSEが画素単位の誤差に着目するのみで、構造的類似度を反映しないためです。これを補うために構造の類似度に着目したものに、 SSIM があります。これは各ピクセル近傍の値のばらつき方の類似を定量化する指標で、構造の類似度をより捉えやすくします。
とはいえ、SSIM も固定的な計算式によるため、人間の知覚と完全に一致するわけではありません。そこで、さらに「人間が感じる画像間の類似性」を定量化できる手法として期待されるのが、Perceptual Lossです。
Perceptual Loss の原理
AI (VGG) による「直感」の定量化
人間の直感的な画像認識を数式化するのは困難ですが、Perceptual Loss は、画像認識に優れた訓練済みのニューラルネットワーク(VGG: ソースコード)を活用することで、これを実現しています。VGGは、オックスフォード大学の Visual Geometry Group が2015年に開発したモデルで、層の深さに応じて VGG11 / VGG16 などがあります。
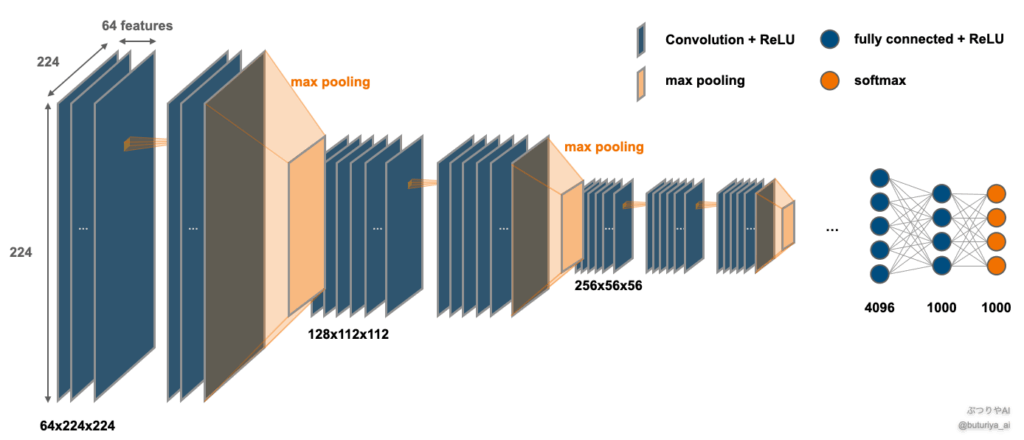
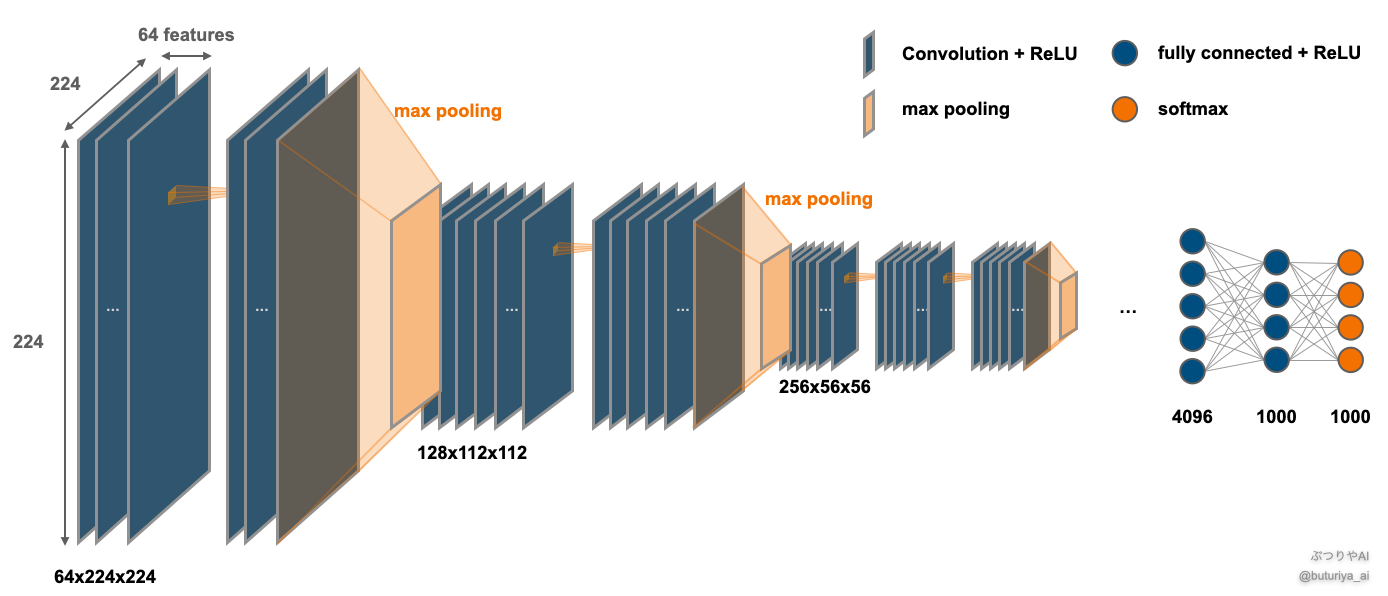
Perceptual Lossで使われる、VGG16の特徴マップ
VGG は RGB 入力画像から豊富な特徴量を抽出し、1000クラスに分類できます。したがって、画像の構造やテクスチャーを抽出する能力に長けていると考えられます。実際、訓練済みモデルに犬の画像を入力し中間層の特徴マップを可視化すると、浅い層ではザラつきや質感といった局所的特徴が、深層に進むにつれて輪郭や意味的構造が抽象的に表現されていく様子がわかります。

特徴マップを利用した損失の計算
各特徴マップの意味を解釈するのは難しいですが、モデルが画像認識のために学習した構造が反映されているのは明らかです。そこで、比較したい2つの画像を訓練済みのVGGモデルにそれぞれ入力し、中間層の特徴マップ間の絶対誤差を積算することで、人間が直感的に感じる構造・テクスチャーの差異を定量化できます。これをPerceptual(知覚的)Loss(損失)と呼びます。
Perceptual Loss の実装
以下では、VGG16 を用いた Perceptual Loss のクラスを PyTorch で実装した例を紹介します。訓練済みの VGG16 モデルをダウンロードして vgg16.pth という名前で保存し、クラスのインスタンスを作成する際に path 引数として指定します。
コードは大きく次のブロックに分かれています:
- VGG16 モデルのロードとブロック分割
- 標準化および画像サイズの調整
- 特徴マップおよびスタイルマップに基づく損失計算
次のセクションでは、これらの詳細なコードブロックとその役割を順に説明していきます。
PyTorch に不安のある方は、以下の記事を御覧ください。
PyTorchモデルの全体構造と作り方|nn.Module・Sequential・ModuleListを図解で理解 – ぶつりやAI
import torch
import torchvision
import torchvision.models as models
class VGGPerceptualLoss(torch.nn.Module):
def __init__(self, path='/content/drive/MyDrive/VGGPerceptualLoss/vgg16.pth', resize=True):
super(VGGPerceptualLoss, self).__init__()
# load trained model
# load vgg into cuda if available, load into cpu if cuda not available
if torch.cuda.is_available():
self.vgg = models.vgg16().to('cuda')
else:
self.vgg = models.vgg16().to('cpu')
self.vgg.load_state_dict((torch.load(path)))
self.vgg.eval() # モデルを評価モードにする。
# preparation to get feature maps from the middle of the model
blocks = [
self.vgg.features[:4],
self.vgg.features[4:9],
self.vgg.features[9:16],
self.vgg.features[16:23]
]
# No grad to prevent back propagation
for bl in blocks:
for p in bl.parameters():
p.requires_grad = False
# Combine the blocks into ModuleList
self.blocks = torch.nn.ModuleList(blocks)
self.transform = torch.nn.functional.interpolate
self.resize = resize
self.register_buffer("mean", torch.tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1))
self.register_buffer("std", torch.tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1))
def forward(self, input, target, feature_layers=[0, 1, 2, 3], style_layers=[]):
# shape の調整
if input.shape[1] != 3:
input = input.repeat(1, 3, 1, 1) # model output
target = target.repeat(1, 3, 1, 1) # ground truth
# ピクセル値の標準化
input = (input-self.mean) / self.std
target = (target-self.mean) / self.std
# 画像サイズの調整
if self.resize:
input = self.transform(input, mode='bilinear', size=(224, 224), align_corners=False)
target = self.transform(target, mode='bilinear', size=(224, 224), align_corners=False)
loss = 0.0
x = input
y = target
# 順伝搬 (forward propagation)
for i, block in enumerate(self.blocks):
x = block(x)
y = block(y)
if i in feature_layers:
# add loss by using the feature map in the middle of the model
loss += torch.nn.functional.l1_loss(x, y)
if i in style_layers:
# add loss by using the "style layer" calculated from the feature maps
act_x = x.reshape(x.shape[0], x.shape[1], -1)
act_y = y.reshape(y.shape[0], y.shape[1], -1)
gram_x = act_x @ act_x.permute(0, 2, 1)
gram_y = act_y @ act_y.permute(0, 2, 1)
loss += torch.nn.functional.l1_loss(gram_x, gram_y)
return loss中間層の準備
モデルそのものは torchvision.models にすでに用意されている VGG16 を使用し、保存しておいた訓練済みのパラメータを load_state_dict で読み込みます。モデルを評価モード(.eval())に切り替えた後、VGG16 を複数のブロック(blocks)に分割してリストとして保存しておきます。これにより、後ほど特徴マップを個別に取り出すことができます。
VGG16 の中間層(Conv2D や ReLU の繰り返し)は、features という名前で定義されており、以下のドキュメントでも確認できます:
torchvision.models.vgg — PyTorch Docs
Perceptual Loss の計算中に VGG16 の重みが更新されないように、分割した各ブロックのすべてのパラメータについて requires_grad = False を設定して、勾配計算が行われないようにします。
最後に、これらのブロックを torch.nn.ModuleList にまとめて self.blocks に格納し、順番に特徴マップを計算できるようにします。
import torchvision.models as models
# モデルをロード
if torch.cuda.is_available():
self.vgg = models.vgg16().to('cuda')
else:
self.vgg = models.vgg16().to('cpu')
# パラメータをロード
self.vgg.load_state_dict((torch.load(path)))
self.vgg.eval() # モデルを評価モードにする。
blocks = [
self.vgg.features[:4],
self.vgg.features[4:9],
self.vgg.features[9:16],
self.vgg.features[16:23]
]
# No grad to prevent back propagation
for bl in blocks:
for p in bl.parameters():
p.requires_grad = False
# Combine the blocks into ModuleList
self.blocks = torch.nn.ModuleList(blocks)Forwardで順伝搬
ここで、x および y はそれぞれモデルの出力画像と正解画像(前処理済)です。これらを self.blocks に格納された VGG16 の各ブロックに順番に通し、特徴マップを抽出します。
x = block(x) や y = block(y) によって得られるのが特徴マップであり、これらの差を L1損失として加算し、Perceptual Loss を構成します。
# 順伝搬 (forward propagation)
for i, block in enumerate(self.blocks):
x = block(x)
y = block(y)
if i in feature_layers:
# add loss by using the feature map in the middle of the model
loss += torch.nn.functional.l1_loss(x, y)この処理により、画像の高次特徴がどれだけ似ているかを損失として捉えることができます。
Style Transfer
Perceptual Loss の原論文では、Style Transfer(スタイル変換) という応用技術も提案されています。これは、出力画像の「内容」は保持しつつ、「スタイル(画風)」だけを別の画像に似せるというもので、例として写真をアニメ風や油絵風に変換することができます。
具体的には、各ブロックから得られた特徴マップ同士の「スタイル(相関構造)」を Gram行列として定義し、その差を L1損失として計算します。これにより、「スタイルの違い」を損失として表現することができます。
if i in style_layers:
# add loss by using the "style layer" calculated from the feature maps
act_x = x.reshape(x.shape[0], x.shape[1], -1)
act_y = y.reshape(y.shape[0], y.shape[1], -1)
gram_x = act_x @ act_x.permute(0, 2, 1)
gram_y = act_y @ act_y.permute(0, 2, 1)
loss += torch.nn.functional.l1_loss(gram_x, gram_y)この処理により、スタイルだけを揃えることも、Perceptual Loss(内容)と組み合わせて両方を揃えることも可能になります。
Perceptual Loss の実用例
超解像(Super Resolution)
超解像とは、低解像度の入力画像から高解像度の出力画像を生成する技術です。たとえば、256×256 の画像から 512×512 の画像を再構成するような問題で、ディープラーニングによる画像処理の代表的な応用の一つです。
このような問題は ill-posed(解が一意に定まらない) であり、細部の再現性が不十分となる場合があります。
こうした状況でも、Perceptual Loss は、人間が「自然」と感じる構造が一致するように学習させることができます。特に、ESRGAN では、GAN(敵対的ネットワーク)と Perceptual Loss を組み合わせることで、細かな構造を再現する性能が大きく向上することが報告されています。
さらに、VGG の中間層出力から特徴を得る際には ReLU 直前(Conv2Dの出力) を使うことで、画像の明暗やエッジがより忠実に再現されると報告されています。
ノイズ除去
ノイズ除去は、日常の写真だけでなく、CT や MRI などの医療画像にも広く応用されています。
例えば、CT画像への応用例では、Perceptual Loss のみを使用した場合にはグリッド状のアーティファクトが残ることがあり、MSE + Perceptual Loss を併用することで、自然で高品質な画像が得られることが報告されています。
Style Transfer
Style Transfer(スタイル変換)は、出力画像の「内容」を保持しつつ、「スタイル」(色使いや質感)を別の画像から学習させる技術です。Perceptual Loss の代表的な応用として知られています。
例えば、写真をジブリ風や印象派風に変換したり、アニメの作風を模倣することが可能です。これは、画像の構造とスタイルの類似性を特徴マップから定量化できる Perceptual Loss の強みを活かした例です。
まとめ
本記事では、Perceptual Loss の背景、原理、実装方法、そして応用例を詳しく解説しました。ピクセル単位での誤差評価にとどまらず、「人間の知覚に基づく類似性」を損失関数として導入することで、より高品質な画像処理が可能になります。
特に、VGG の中間層から得られる特徴マップを用いることで、画像の 構造的・意味的特徴 を活かした訓練ができる点が重要です。
また、Style Transfer をはじめとする様々な応用により、Perceptual Loss は単なる損失関数ではなく、画像理解と生成の鍵となる技術として注目されています。
ディープラーニングを用いた画像処理において、表現力を一段階引き上げたいと考えるすべての実践者にとって、Perceptual Loss は極めて有用なツールと言えます。
引用
Perceptual Loss:

VGG:

超解像:

デノイズ:

コメント