ディープラーニングを学ぶと必ず登場する「Tensor(テンソル)」。
「Numpy じゃダメなの?」
「Tensor って具体的に何ができるの?」
この記事では、そんな疑問を解決するために、PyTorch の Tensor の基本と Numpy との違い、使い方の基礎を、図やコード例を交えてわかりやすく解説します。本記事の内容は以下のとおりです。
- なぜ Tensor か? Numpy との違い
- GPU による高速化のメリット
- 自動微分との関係
- Tensor の基本的な使い方 (Tensor の作成・計算・CPU/GPU 切り替えなど)
torch.zeros,torch.ones,from_numpysum,mean,std,itemclone,detach,to('cuda')
<関連記事>
Tensor の自動微分について知りたい方はこちら:
<この記事で扱う主要なモジュール・ライブラリ一覧>
import torchTensorとは?
Tensor とは PyTorch で使われる多次元配列のデータ構造で、 torch.Tensor 型です。Numpy の ndarray と非常に似ており、スカラー、ベクトル、行列などを表現でき、演算、統計量の計算も簡単に行えます。
なぜNumpyではなくTensorか?
GPUによる高速計算が可能
Tensor を使うことでデータを GPU に転送して処理できます。GPU を使うことで、ディープラーニングで必須となる大量の行列演算を高速に行う事ができるようになります。
自動微分
PyTorch の Tensor は、微分の際にチェインルールでどのように変数をたどるかを記録した計算グラフを自動的に構成します。これにより、関数の勾配(微分)を自動で計算し、自分で実装することなく誤差逆伝播を学習させることができます(PyTorchモデルの全体構造と作り方|nn.Module・Sequential・ModuleListを図解で理解 – ぶつりやAI)。
Tensor の基本操作
Tensor の多くの操作 (shape, dim など) が Numpy と同じです。以下、避けては通れない最重要の機能について説明します。
Tensor の作り方
import numpy as np
import torch
# 0で初期化されたTensor
x_tensor = torch.zeros([2, 3], dtype=torch.float32) # 2x3の0行列
# 1で初期化されたTensor
x_tensor = torch.ones([2, 3], dtype=torch.float32) # 2x3の1行列
# 値を指定して作成
x_tensor = torch.tensor([[-3, 0, 5], [1, 7, 3]]) # 2x3の行列NumpyからTensorに変換
x_numpy = np.zeros([2, 3], dtype=np.float32)
# メモリを共有せず(安全)
x_tensor = torch.tensor(x_numpy) # x_tensorとx_numpyの値は独立
# メモリを共有(注意)
x_tensor = torch.from_numpy(x_numpy) # x_tensorとx_numpyの値は連動tensor の演算とブロードキャスト
基本演算 (加減乗除)
x_tensor = torch.tensor([1, 1], dtype=torch.float32)
y_tensor = torch.tensor([2, 2], dtype=torch.float32)
x_tensor + y_tensor # [1, 1] + [2, 2] = [3, 3]
x_tensor - y_tensor # [1, 1] - [2, 2] = [-1, -1]
x_tensor * y_tensor # [1, 1] * [2, 2] = [2, 2]
x_tensor / y_tensor # [1, 1] / [2, 2] = [0.5, 0.5]ブロードキャスト
# 行列の全要素にスカラーの演算が適用される
x_tensor + 10 # [1, 1] + 10 --> [11, 11]
x_tensor / 10 # [1, 1] / 10 --> [0.1, 0.1]統計量
値の取り出しには .item() を付け加えます。つけなければ、スカラーの Tensor が返されます。
torch.sum(x_tensor).item() # 合計
torch.mean(x_tensor).item() # 平均
torch.std(x_tensor).item() # 分散Tensor のデバイス (CPU・GPU) の切り替え
ディープラーニングで GPU を使う場合、普通のパソコン、つまり CPU、HDD、メモリのセットに、GPU がくっついています。GPU でデータを処理するには、コード上で命令する必要があります。GPU を使う場合、Tensor の作成時の直接指定するか、あとで CPU から GPU に切り替えます。
x_tensor = torch.zeros([2, 3], device='cuda') # GPUでtensorを作成
x_tensor = x_tensor.to('cpu') # データをCPUへ転送
x_tensor = x_tensor.to('cuda') # データをGPUへ転送
# GPUを複数搭載しており、使用するGPUを指定したい場合
# 番号を指定できる。
torch.zeros([2, 3], device='cuda:0')
if torch.cuda.is_available(): # GPUが利用可ならTrueを返す
x_tensor = x_tensor.to('cuda')なぜ “gpu” ではなく “cuda”?
PyTorch では、GPU を指定する際に "cuda" という文字列を使いますが、これは「NVIDIA の CUDA(Compute Unified Device Architecture)」という技術を使うためです。
CUDA は、NVIDIA が開発したGPUのためのプラットフォームで、PyTorch はその上で動作するように設計されています。そのため、デバイス指定も "cuda" という名前で統一されているのです。
つまり、"cuda" は「GPU を使う」というより、「CUDA 対応の NVIDIA GPU を使う」ということになります。
自動微分に関係するdetach()とclone()
Tensor の変数でできた関数を微分すると、チェインルールに基づいて関数内をたどり、その変数について自動で微分できます。
しかし、学習とは切り離して推論の結果などを取り出したいときもあります。微分機能がオンのままだと、逆誤差伝搬を通して学習(モデル)に影響を及ぼしてしまうおそれがあるためです。
detach()
そこで、テンソルに.detach()を加えると計算グラフから切り離され、微分機能がオフになります (文字通り detach は”切り離す”という意味)。下の例では、y_tensor_detachedは変数x_tensor から「微分・チェインルール」という意味で切り離されています。
y_tensor = x_tensor ** 2
# 二次関数の結果を計算グラフから切り離す
y_detached = y_tensor.detach()※ここで紹介した.detach()は「自動微分」の仕組みと関係しています。Tensor の微分や勾配計算の詳細については、次回記事(近日公開)で詳しく解説します。
clone()
モデルの出力をコピーして2種類の損失関数をつくったりと、いろんなアレンジをしたくなることがあります (下図)。この場合、誤差逆伝搬をするときに、コピーした Tensor も経由(青矢印)して勾配を求める必要があります。clone()はテンソルを新しくコピーしますが、計算グラフにはつながっており、微分が伝搬します。
# 計算グラフにつなげたまま二次関数の結果を複製する
y_tensor_cloned = y_tensor.clone() 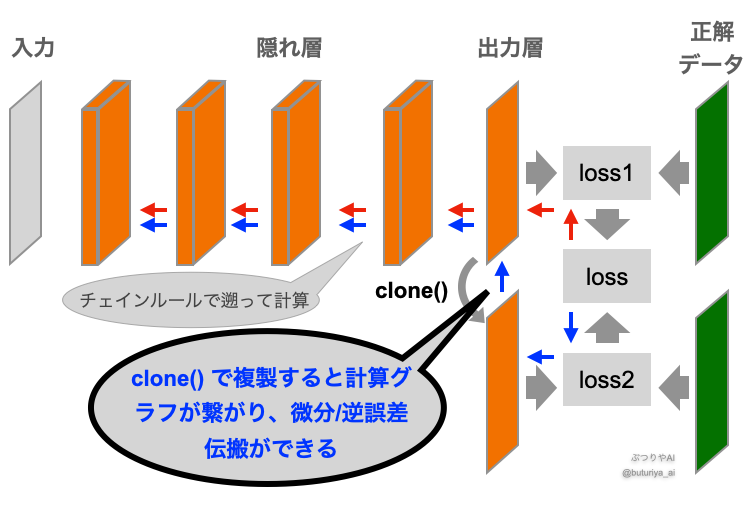
detach + clone (完全に独立したコピー)
detach().clone()により計算グラフから切り離されたコピーを作れるため、出力結果などを安全に扱うことができます。
# 二次関数の結果を計算グラフから切り離して複製 (z_tensor, x_tensorとは完全に独立)
z_tensor_detached_cloned = z_tensor.detach().clone()仮に上の図中のcloneをdetach().clone()に差し替えれば、青矢印に沿って微分や誤差逆伝播を行うことはできなくなります。
まとめ
PyTorch の Tensor は、ディープラーニングを強力に支えるデータ構造です。基本的な操作は Numpy と共通しますが、微分機能や GPU へのデータ転送など、ディープラーニングならではの違いもあります。
コメント