ディープラーニングの実践に進む前に、実用上の理論やフレームワークを理解することが重要 です。特に「過学習(Overfitting)」は、ディープラーニングの学習において最も重要な問題の一つであり、適切な対策をしなければ、モデルの性能は大幅に低下してしまいます。
本記事では、過学習とは何か、そしてそれを防ぐための手法であるバリデーション(Validation) について解説します。
ディープラーニングをより基本的な理論から学びたい方は、ディープラーニング入門【初心者向け】 の「理論基礎編」を御覧ください。
フィッティング
理論のあるフィッティング
フィッティングとは、複数のデータの間の因果関係を、数式でできるだけ適切に表現することを指します。データに対して、あるパラメーターを持つ数式をフィット(最適化) させることで、関係性をモデル化します。
例えばオームの法則:
$$V = RI$$
を考えてみましょう。\(V\) は電圧、\(R\) は抵抗値、\(I\) は電流で、電圧は電流に比例します。実験によって様々な電流 \(I\) を流し、電圧 \(V\) を測定すると、データ点が得られます。これらのデータを用いて、関数 \(V = f(I | R)\) をフィッティングすると、最適な \(R\) の値を推定できます。
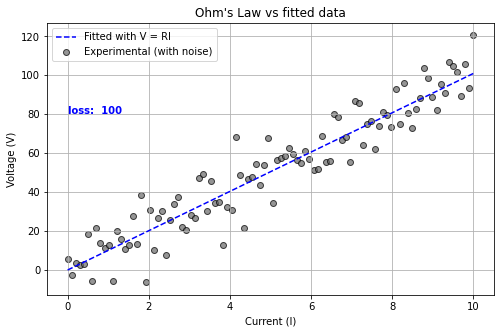
ディープラーニングのフィッティング
(教師あり)ディープラーニングも基本的にはこのフィッティングと同じです。実際、インプットとアウトプットを1変数、活性化関数を \(y = x\)、バイアスを0に固定し、中間層をなくせば、オームの式と同じになります。
しかし、一般的にディープラーニングは、きれいな理論式では表せないような複雑な因果関係のものに適応されるため、無数のパラメーターを持たせて自由度を高めたアプローチになっています。
言い換えると、ディープラーニングは、理論的に厳密な数式によるモデル化を放棄し、あらゆるパターンを捉えるために膨大なパラメーターを持たせた手法 だといえます。
良いフィッティングとは?
ここで、「オームの法則を知らない状態で、複雑な関数を使ってデータをフィッティングするとどうなるか?」を考えてみます。ディープラーニングと全く同じ戦法です。最も簡単な方法は、多項式を使うことです。
\(y = f_n = a_0 + a_1 \cdot x + a_2 \cdot x^2 + \cdots a_n \cdot x^n\)
上はn次の多項式と呼ばれます。さて、とりあえず十分に複雑な現象でも表せるように、80次の多項式で先ほどと同じデータ点をフィッティングしたら、以下のようになりました。
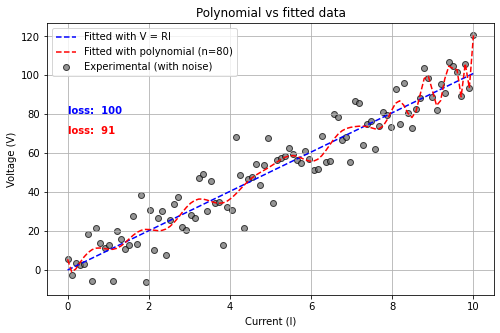
良いフィッティングのために
過学習(Overfitting)とは?
上で感じた不安を確かめるために、もう一度同じ実験をして、先ほどフィッティングしたモデルはそのままに、新しいデータを重ねて見てみましょう。
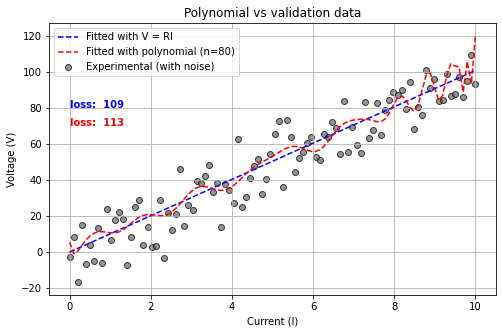
先ほどとそっくりですが、データ点のばらつき方だけが変わっています。そして、損失 (loss) を比較すると、直線モデル(青)のほうが良い値を示しています。
これは、このデータ点の本質が直線であり、そこからのズレはノイズだからです。多項式は測定するたびにランダムにばらつくノイズまで説明しようとしてしまったために、測定を改めてノイズが変わった途端に損失が悪くなってしまうのです。これを「過学習(オーバーフィッティング)」といいます。
このように、モデルがたくさんのパラメーターを持っていて、極めて複雑な関係を説明できてしまう、というのは、諸刃の剣でもあるのです。過学習の問題点を改めて整理すると、次のようになります:
- フィットしたデータの損失(loss)は非常に小さくなるが、関数が無意味に複雑になる
- 新しいデータの損失(loss)が大きくなり、よく説明できない
つまり、フィットしたデータのノイズまで説明してしまい、本来の規則性を捉えられなくなってしまう のです。実はこの実験で用いた2つ目の新しいデータが、次に説明する「バリデーションデータ」に相当します。
バリデーション(Validation)とは?
過学習を監視するための基本的な手法が、バリデーション(Validation)です。ディープラーニングでは、モデルの学習を進める際に、フィッティングに用いないデータを用意し、学習の間に損失をモニタリングします。
このデータを バリデーションデータ(Validation Data)と呼びます。したがって、学習に必要なデータは以下の2つになります。
- 訓練データ(Training Data): モデルを学習させるために使用するデータ
- バリデーションデータ(Validation Data): 学習中のモデルの性能を確認するためのデータ(モデルのパラメーター更新には使わない)
訓練データでパラメーターを更新するたびに、バリデーションデータで損失を計算し(Validation Loss)、本当の性能をモニタリングするのです。例えば Validation Loss が上昇し始めたら学習を自動で止める「Early Stopping」 という手法などに使われたりします。
過学習を防止するには?
学習中、validation loss などを監視する、あるいは記録することで、過学習が起きたかどうかをいち早く検知することができます。もし過学習を防ぐには様々な手法がありますが、その中でも最も基本的なのは、データを増やすこと、そしてデータの多様性を確保することです。
先ほど多項式でフィッティングをしたら過学習が起きたのは、自由度(パラメータの数)が高すぎたからでした。じつは多項式のパラメータの数がデータ数と同じだと、すべてのデータ点を通るようにフィッティングできてしまいます。このように、自由度が高すぎるかどうかは、データの数で決まります。データが十分に多ければ、過学習のリスクは減ります。
しかしデータを増やすことで過学習を防げるのは、多様性が確保される前提です。例えば画像認識でネコを判別するモデルを考えましょう。もし特定の種類のネコの画像だけでトレーニングをしたら、他の種類のネコは認識できなくなるかもしれません。これはデータにバイアスがあれば、結局特定のパターンに過剰にフィットしてしまいます。こういう状況を、データにバイアスがある、といいます。
まとめ
- フィッティングとは、データの間の関係を数式で表現すること
- 過学習(Overfitting)は、モデルがノイズまで学習してしまう現象
- バリデーション(Validation)によって、過学習をモニタリングできる
過学習を避けるための手法は他にもたくさんありますが、それらは別の記事で詳しく解説していきます!
おすすめカテゴリー

コメント