 ディープラーニング
ディープラーニング 【実践基礎10】PyTorchでモデルを訓練する方法|GPU・DataLoader・訓練ループを体系的に理解
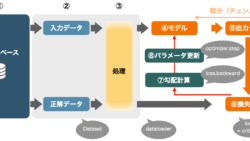
PyTorchでのモデル訓練の全体像をステップバイステップで解説。GPU設定、DataLoaderの使い方、損失関数や訓練ループの組み立て方までを丁寧に紹介します。初心者が次のレベルに進むための必読ガイドです。
ディープラーニング 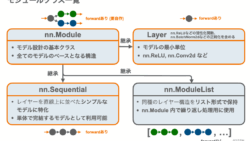 ディープラーニング
ディープラーニング 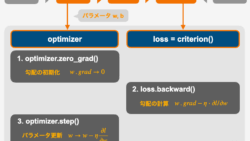 ディープラーニング
ディープラーニング 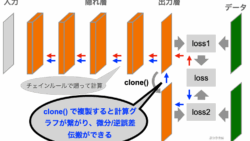 ディープラーニング
ディープラーニング 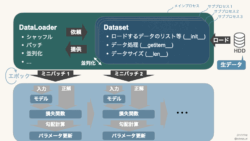 ディープラーニング
ディープラーニング 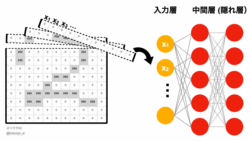 ディープラーニング
ディープラーニング  ディープラーニング
ディープラーニング 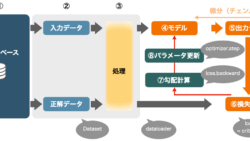 ディープラーニング
ディープラーニング 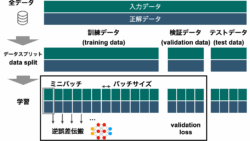 ディープラーニング
ディープラーニング 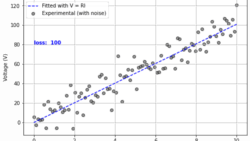 ディープラーニング
ディープラーニング